快手 KAT-Coder-Pro V2 模型测试
市面上几乎没人聊这个模型,反倒让我很好奇,我决定全面测评使用一下
StreamLake
StreamLake溪流湖是快手toB视频云平台,提供领先的音视频AI解决方案。包含KAT-Coder智能编程助手、万擎大模型平台、视频云服务、直播云、点播云、实时音视频RTC等产品。基于前沿AI技术和音视频算法,为企业提供智能代码生成、视频处理、内容理解、智能审核等全链路服务,助力数字化转型。

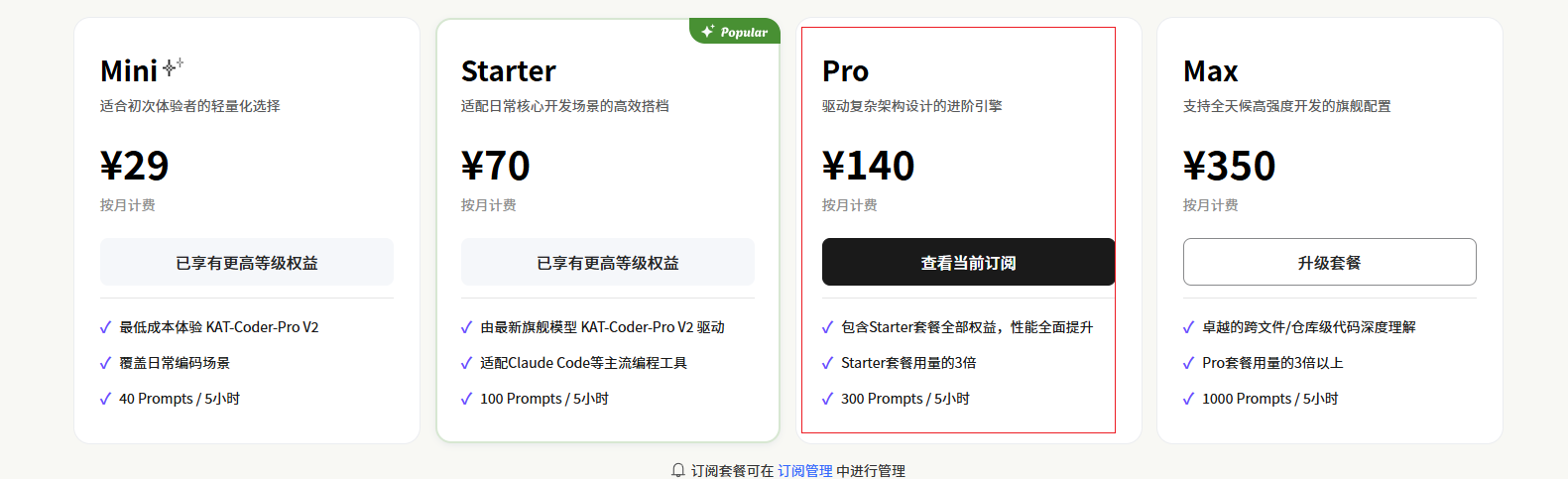
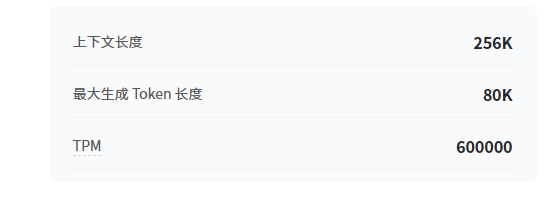
付完款发现上下文只有256K , 到今天来说 已经落后了
而且不支持视觉,也没有mcp接入 联网搜索之类的东西
确实是远远落后了
时隔半年再次看快手模型的官网,发现现在几乎就主打这一个模型了 coding plan用这个,然后api 调用这个是, 接入openclaw 也是这个,总之一个模型走天下,看上去太穷了,像是随时跑路的状态,但其实我很喜欢这种方式, 一个模型通杀所有场景 哈哈哈
接入 opencode 中使用
开了一个新的项目,决定保守一点,先让写文档, 之后再生成代码
下面是实际的体验
- 不断 chat 需求来说, 我觉得理解能力没问题,和市面上的一流模型没有明显差距
- 表现好的地方是 我在开始强调 他需要的时候可以追问 和批判精神的来接受后续的需求说明,他确实按照要求做了,虽然有些死板了,但是确实是朝着正确的方向在努力,这说明在听从指令方面做得优化很好, 如果是 opus 4.6 的话,会有更多模型本身的想法,对用户输入的更多是参考,不会像这么像是作为系统级的指令来对待, 快手模型在很多场景下 这个会是优势,短平快的时候,很容易让人想到 api 调用

- 项目很小,我的一条又一条的 prompt 非常的耐心,所以最后它是明白了整体的需求的, 当模型最终理解了我的需求之后,能感受到它和市面上的一流模型的差别了,就是它的肚子里东西不太多, 没有掏出非常一流的方案来,并且有一种想要匆匆结束的感觉,就是说那种觉得任务结束了,在最需要思考 斟酌 补充信息 思考是否真实可行的时候 表现的太保守了, 当然也可能我对这个新的项目太熟悉了 是我能力范围内的,总之快手模型没有让我表现出新鲜感来
- 做的很不好的地方就是工具调用了,我已经十分明确说明了他需要落地文档,没想到它居然控制台直接输出了,当我再次强调落地本地的时候,它居然先去获取了路径 居然让我确认路径是什么, 作为付费的商用模型可以说是让人大跌眼镜了,或许这个里面有opencode本身的原因,之前用 gpt5.4 的时候就调用工具比较保守,但是口头让用户确认路径 这个体验太差了,纯纯的官方浪费token

- 看最后落地的文档来说,目的肯定是达到了,缺点:它甚至没有写要用到什么技术栈,也没有让我补充这一信息,纯粹把这个最重要的东西忽略过去了,然后对于入参的某些很重要的属性 也是自己自己瞎编。
- 还有一个最大的问题 信息更新的太慢了,至少是三个月前的,对现在日益更新的 LLM VLM 能力不了解,出方案就会很保守
总结: 能感觉到 快手模型 接入 opencode 明显水土不服,上下文消耗也没法看,但是模型本身的能力还远远没有被释放出来
接入 claude code 使用
生成代码的部分 我们换 claude code,文档就用上次生成的
- 直观感受是慢 生代码慢 只是简单的项目 build 起来都这么慢,而且我本身就是国内网络,这个表现让人难以理解,但是矛盾的事 打字chat 需求的时候 又挺快的
- 生成的后端代码错误频出, 连续修改了两次 都没办法直接运行
- 发生了一次直接中断

- 最后的默认情况下 自己使用了 sqllite ,我觉得其他模型的话 会直接放到内存,后期用什么具体的数据库再和人商量
- 前端代码至少已经修改两次了 也没和后端对接上
我没有耐心再继续调教了 我决定换 codex 了
不过在 claude 里面 这个模型的工具调用好了很多,这个和agent 本身的能力有关
生成代码 最大的体会就是 技术积累太老旧了,想在这样的模型身上擦出一些火花是很难的事情, 也没有机会跟他头脑风暴和学到一些东西了
最后
买这个最大目的是我觉得国内的肯定会是速度快很多的,但是在claude code 里面生成代码的时候 没有感受到速度,这个是最令我失望的,没人聊这个模型是有原因的
后续我有三个计划更合理的使用快手模型:
- 做个中间件,搞mcp 或者其他形式 让其他模型 来指挥它干活,完成一些具体的事情,搞成永动机
- 接入 openclaw , 官网上写了对龙虾做了优化,但是经过今天的测试后 我不太相信它的具体能力会有多强了
- 纯当接口用,做api 调用 清洗我本地的一些离线数据,做数据标注
降级为这个模型之后 干活不给力 纯浪费人世间,很容易情绪上产生波动,这个时候 耐心 是很重要的,并不是快手模型弱 ,而是我没有把它放到对的地方上
 陕公网安备61011302002223号
陕公网安备61011302002223号